Random forest
L'algoritmo random forest è un algoritmo classificatore del machine learning supervisionato. E' usato nei problemi di classificazione.
A partire da un dataset di apprendimento genera più alberi decisionali (decision tree)
La random forest migliora l'affidabilità del modello rispetto a un singolo albero decisionale.
Come funziona l'algoritmo random forest
L'apprendimento comincia con un dataset superivisionato (training set) composto da n attributi X1,...,Xn (features) e una etichetta (target) che indica la risposta esatta.
Fase 1
Nella prima fase l'algoritmo random forest genera gli alberi decisionali
1.1) L'algoritmo sceglie casualmente un campione di esempi dal dataset e un sottoinsieme (i<n) di attributi.
1.2) Su questo campione di dati D1 elabora un algoritmo decisionale e registra il risultato.

Il processo si ripete una seconda volta.
L'algoritmo torna al punto 1.1 per generare un nuovo campione di dati D2 ed elaborare un altro albero decisionale.
Il nuovo albero decisionale può essere uguale o diverso dal precedente.
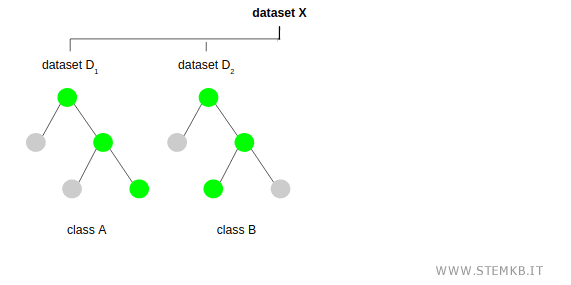
Il processo si ripete molte volte.
Alla fine dell'iterazione l'algoritmo ha generato molti alberi decisionali (decision tree) a partire da diversi campioni casuali del dataset originale.
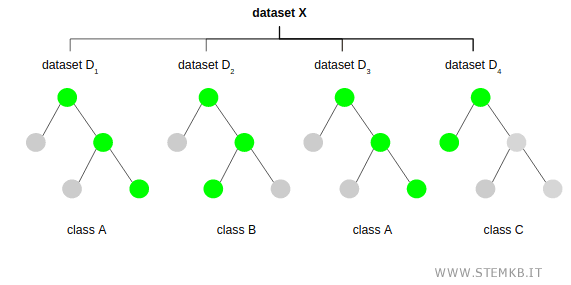
Ogni albero decisionale indica una soluzione (o classe) che può essere uguale o diversa dalle altre.
Da questo deriva il termine random forest (foresta casuale di alberi decisionali).
Fase 2
Nella fase 2 l'algoritmo Random forest seleziona la soluzione più frequente negli alberi decisionali.
Ad esempio, in questo caso la soluzione più frequente è la classe A, perché si presenta in due alberi decisionali, mentre le classi B e C si presentano una sola volta .
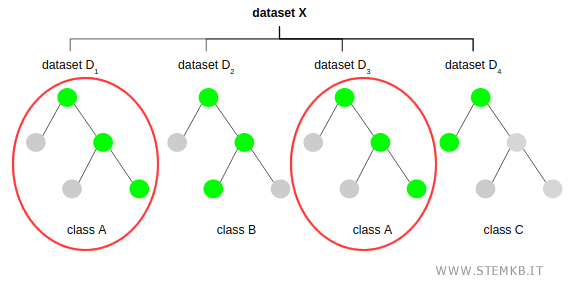
Quindi, l'output finale dell'algoritmo di random forest è la classe A.
Vantaggi e svantaggi
L'algoritmo di random forest riduce la varianza del modello previsionale ma aumenta il BIAS.
Un'elevata varianza è causa di adattamento eccessivo ai dati (overfitting) durante l'addestramento. Un elevato BIAS indica che il modello non ha indivuato dei pattern nei dati (underfitting).




 Machine Learning
Machine Learning