Overfitting
L'overfitting si verifica quando il modello ottenuto con il machine learning è eccessivamente vicino ai dati di training e poco generalizzabile ad altri casi.
Un esempio pratico
Abbiamo una serie di dati di training da elaborare.
Ogni dato è composto da due caratteristiche ( altezza e peso ).

Usiamo il machine learning per trovare un modello in grado di stimare il peso di una persona in base all'altezza.
L'algoritmo di apprendimento elabora i dati di training e crea un modello predittivo f(x) senza compiere errori.
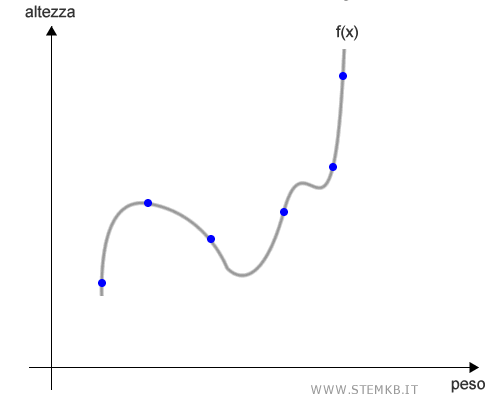
Nota. In questo caso il modello è una semplice funzione f(x) che elabora l'altezza in base al peso. $$ altezza = f(peso) $$
Il modello sembra adattarsi bene ai dati di training.
Tuttavia, se testiamo il modello con altri dati, i dati di test, il modello compie molti errori.
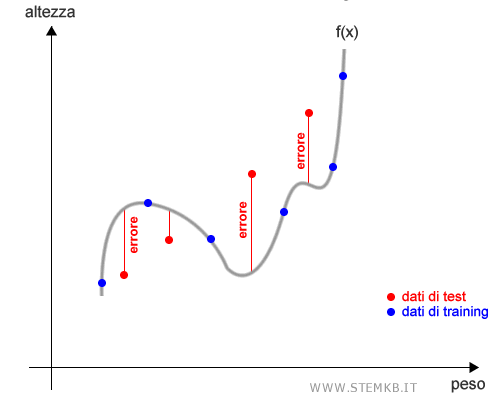
Questo vuol dire che il modello è molto vicino ai dati di training ma poco generalizzabile ad altri casi.
In questo caso si parla di overfitting ossia eccessivo adattamento.
Nota. In questo esempio è stato descritto l'overfitting in un problema di regressione. L'overfitting può presentarsi anche nei problemi di classificazione.
Come risolvere l'overfitting
Generalmente l'overfitting si risolve eliminando qualche caratteristica (features) dal dataset di training ed elaborando un nuovo modello predittivo g(x).
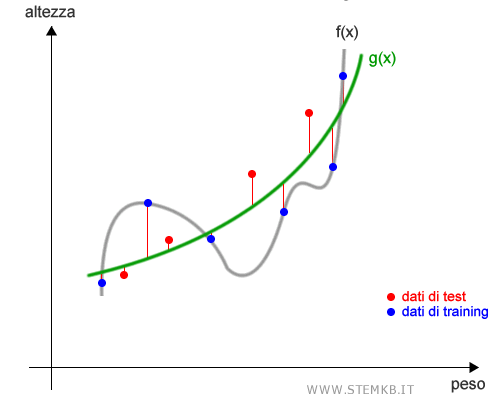
Il nuovo modello predittivo g(x) ottenuto con meno features è meno preciso rispetto al precedente.
Si adatta meno ai dati di training ma è più generale.
Il margine d'errore è minore quando lo utilizziamo sui dati di test.




 Machine Learning
Machine Learning